
官方网站机器东谈主主张股局部活跃-九游")


AIxiv专栏是机器之心发布学术、期间内容的栏目。畴昔数年,机器之心AIxiv专栏领受报谈了2000多篇内容,掩饰群众各大高校与企业的顶级施行室,有用促进了学术相易与传播。淌若您有优秀的责任想要共享,接待投稿不祥关系报谈。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
跟着深度学习大言语模子的越来越火爆,大言语模子越作念越大,使得其推理资本也水长船高。模子量化,成为一个热点的接洽课题。
近日,字节止境语音团队推出一个全新的量化念念路,烧毁传统的量化范式,从数学优化的角度来对量化任务建模。著述放在了 arXiv,代码也曾开源,可以一键复现文中的总共放浪:

论文邻接:https://arxiv.org/abs/2404.12759
神志邻接:https://github.com/bytedance/decoupleQ
W2 算子:https://github.com/NVIDIA/TensorRT-LLM/pull/1568
1. 配景
大模子的速即发展,使得推理资本越来越高。模子量化,手脚一个裁汰推理资本的期间决议,得到了越来越多的柔顺与接洽。关联词,在传统的量化范式下,模子的精度在极低比特下会速即下落。基于此,作家们提议了一种新的量化念念路,将模子参数解耦为整数部分和浮点部分,从数学优化的角度来对量化任务建模,使得在极低比特下,模子依然能保执较高的精度。这么作念的上风是彰着的,咱们不再需要柔顺量化独到的问题,比如如何惩办敏锐通谈,如何惩办 outlier 等等,而是只需要将量化问题进行数学建模,找到一个妥当的优化标的函数,然后去求解该函数。
2. 传统量化

3. decoupleQ


4. W2 算子完毕
要对量化后的模子进行推理,需要量化算子的救济,在业界莫得现成的 w2a16 的算子可用,作家们基于 Tensorrt-LLM 中的 w4 算子竖立了 w2 的 Gemm cuda kernel, 完毕了 w2a16 模子的高效推理。
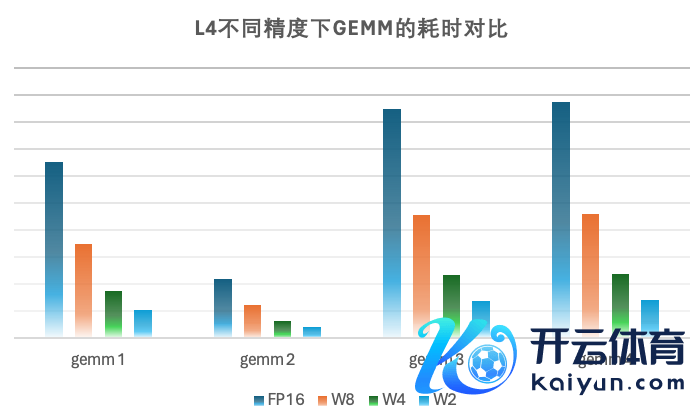
量化模子自己所以 2bit weight 的样貌加载和存储在显存中,因此会占用比较小的显存。咱们的 cuda kernel 通过在初始时将 2bit 的 weight 加载到寄存器中,再行使硬件请示高效改造成 bf16 的样貌与 activation 进行 gemm 运算。因为咱们的场景受限于 latency, generation 阶段的 batchsize 比较小,此时矩阵乘受限于 weight 的访存,这种完毕会大大减少访存量,擢升模子的性能。在完毕历程中,鸠集了算法搜索以及 SpiltK Parallel Reduce,进一步能擢升模子的性能,实测在 batchsize=1 的情况下,在 L 卡上 w2a16 Gemm 性能比较 w4a16 能擢升 1.4x-1.7x 不等。
算子邻接:https://github.com/NVIDIA/TensorRT-LLM/pull/1568

w2 cuda kernel的完毕旨趣
5. 施行
作家在著述给出了字节止境里面的 ASR 施行放浪,和开源的施行对比放浪:
其中里面施行放浪是:

该表格中,作家用 word err rate (WER) 来臆想 ASR 的准确率。作家尝试使用不同的顺序将模子量化为 W2A16g64。量化前的浮点模子的 wer 是 6.68%,使用 GPTQ【1】量化以后是 6.83%,带有 block 最小化的 decoupleQ 量化以后的 wer 是 6.70%,该放浪与量化前的浮点模子的 wer 很接近。同期也 report 了量化所需要的耗时。量化高精度的代价,是量化耗时较长。在骨子业务中,在使用 decoupleQ 对模子量化完毕以后,固定整数部分,使用有标签数据集微调 scale 和 zero,模模子精度有进一步的擢升。
开源对比施行放浪是:

该表格是 decoupleQ 和其他顺序在 Llama-1/2 上的量化放浪比较。以 perplexity (PPL) 手脚评价标的。可以看出,在雷同的量化确立下,deoucpleQ 的 PPL 在绝大多数时辰会低于其他顺序。
6. 业务收益
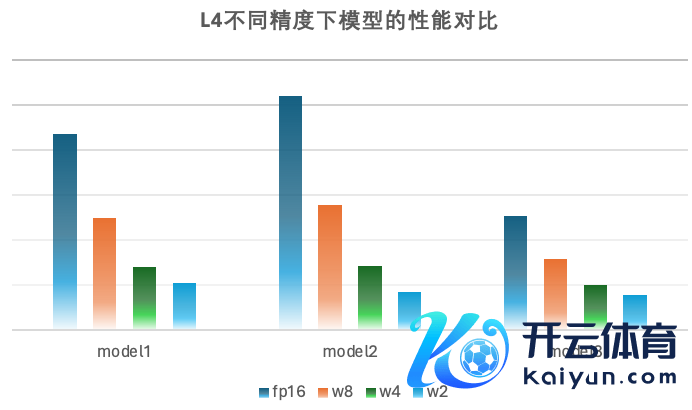
decoupleQ 量化期间在字节止境语音部门当今被平庸使用。也曾上线于语音生成模子(Text-to-Speech),语音识别模子(automic speech recognition)等等,落地于豆包、飞书、抖音等产物中。大都上线业务标明,基于 decoupleQ 的量化,W4A16 的推理精度也曾王人备能和 fp16/bf16 推理执平;W2A16 的精度只略差于 fp16/bf16 精度(对浮点部分 sft 以后,精度能和 fp16/bf16 执平)。尽管论文中只先容了 weight-only 的量化,然则在骨子业务中,在 weight 赢得考究的量化以后,对 activation 的量化也便能粗浅好多。
在硬件加快上比较 fp16、w8fp16、w4fp16 赢得了可以的加快后果,在小 batch 下 w2 矩阵乘的性能比较 fp16 擢升 5-6 倍,比较 w4 擢升 1.5-1.7 倍。在里面业务模子上,w2fp16 比较 fp16 性能有 3-5 倍的擢升, 比较 w4fp16 性能有 1.25-1.4 倍的性能擢升,同期也会使得模子 weight 占用显存大幅下落,为 runtime 的显存行使提供更多空间。
7. 纪念与究诘

参考文件:
【1】Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Optq: Accurate quantization for generative pretrained transformers. In The Eleventh International Conference on Learning Representations, 2022.
【2】Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, and Ping Luo. Omniquant: Omnidirectionally calibrated quantization for large language models. arXiv preprint arXiv:2308.13137, 2023
【3】Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Xingyu Dang, and Song Han. Awq: Activation-aware weight quantization for llm compression and acceleration. arXiv preprint arXiv:2306.00978, 2023.